


Introduction to Artificial Intelligence (AI) and It’s Role in Prostate Cancer Detection and Diagnosis

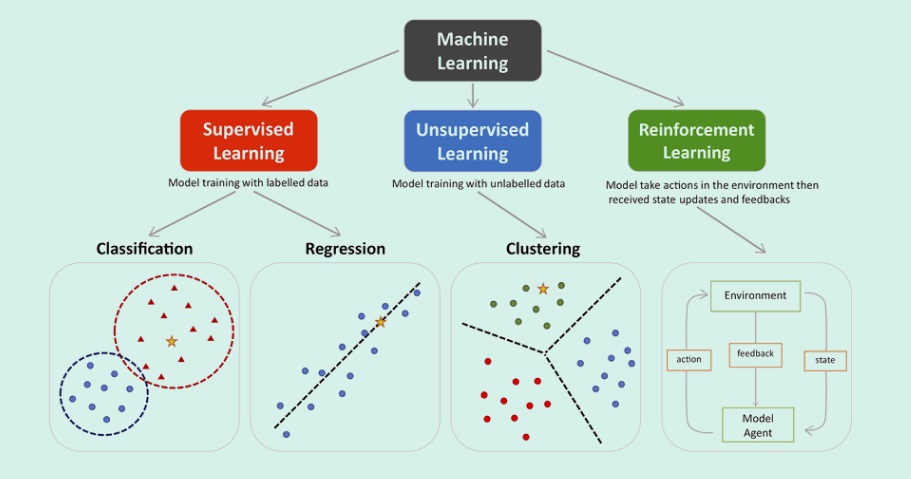
Machine learning encompasses three main types -supervised, unsupervised, and reinforcement. Supervised learning involves classification and regression, where models are trained with labeled data such as MRI image sets with labeled or manually segmented organs and pathologies within. Unsupervised learning focuses on clustering and finding patterns in unlabeled data such as might be found in remote sensing or photographic analyses seeking specific groups. Reinforcement learning improves model performance through interaction with the environment. In the provided visualization, colored dots and triangles represent training data, while yellow stars symbolize new data that can be predicted by the trained model.
We’ll focus on Supervised Learning as this is the type of learning used in training General/Limited memory AI employed in Medical Imaging analyses software such as cancer detection in MR images.

Decision Tree machines
Decision Tree machines are a type of supervised learning algorithm in machine learning that use a tree-like structure to categorize or make predictions based on how a set of questions were answered. They are named for their upside-down tree shape, which has a root node, branches, internal nodes, and leaf nodes.
Decision trees are used for classification and regression modeling:
Classification trees
Determine if an event happened or not, usually with a “yes” or “no” outcome. For example, a decision tree could be used to accept or deny credit applicants based on data like credit score, debt burden, and length of credit history.
Decision trees use a divide and conquer strategy to identify the best split points within the tree, repeating the process in a top-down manner until all records have been classified. The root node starts with a specific question of data, and the branches hold potential answers. The nodes resulting from the splitting of the root node are called decision nodes, which represent intermediate decisions or conditions. The nodes where further splitting is not possible are called leaf nodes, or terminal nodes, and often indicate the final classification or outcome.
Decision trees are popular in machine learning because they are a simple way to structure a model and understand the model’s decision-making process.

RFs use two sources of randomness to ensure that the decision trees are relatively independent:
Bagging
Each decision tree is trained on a random subset of the training set examples, with replacement. This approach is often used to reduce variance in noisy datasets.
Attribute sampling
At each node, only a random subset of features are tested as potential splitters.
To build each tree, RFs also perturb the data set by bootstrapping, which means randomly sampling members of the original data set with replacement. This results in a data set that is the same size as the original, but with a constantly changing version of the data. Each subset, or “bootstrap sample”, may have some data points that appear multiple times, while others may not appear at all.
When making predictions, each tree in the RF votes for a single class, and the RF prediction is the class that receives the most votes. For example, in regression, each tree predicts the value of y for a new data point, and the RF prediction is the average of all of the predicted values.
RFs are used in many different fields, including banking, the stock market, medicine, e-commerce, and finance. However, they do have some disadvantages, such as becoming too slow and ineffective for real-time predictions if there are too many trees. Increased accuracy also requires more trees, which can slow down the model further.
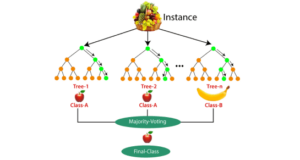
Regression type machines utilize Linear Regression, Neural Network Regression or Support Vector Regression.
Linear Regression
Linear Regression is a statistical technique used in machine learning to find the relationship between variables, or features and a label. It’s a supervised learning algorithm that models a dependent variable as a function of independent variables by finding a line that best fits the data. The line can then be used to make predictions for continuous or numeric variables.
For example, linear regression can be used to predict the price of a house based on the number of rooms it has, or to predict weight based on height and age. In these examples, the dependent variable is the price or weight, and the independent variables are the number of rooms, height, and age.
Linear regression is advantageous when there are at least two variables in the data. It’s used in many fields, including business, science, and data science, to convert data into insights, conduct preliminary analysis, and predict trends.
Here are some steps for using linear regression:
- Plot the data points as a scatter plot
- Draw a line that best fits the data points
- Calculate the error between the actual data points and the predicted data points
- Use the line to make predictions
Gradient Boosting
Gradient Boosting is a machine learning technique that combines multiple models into a single, more accurate model. It’s known for its speed and accuracy, especially when working with complex or large data sets.
Here’s how gradient boosting works:
Initialize
Fit an initial model to the data, such as a linear regression or tree Fit an initial model to the data, such as a linear regression or tree
Build
Create a second model that focuses on predicting cases where the first model did poorly
Iterate
Add new models sequentially, each one attempting to fix the errors of the previous model
Combine
The final prediction is the sum of all the individual predictions from each model. The term “gradient” refers to the method of using the gradient of the loss function to minimize errors during training. The “boosting” part of the name refers to the algorithm’s ability to combine weak models to create a strong learner. Gradient boosting is often used for regression and classification problems. It’s also suitable for datasets with missing values or noisy data points because it treats missing values like any other value.
Neural Network Regression
Neural Network Regression is a machine learning technique that uses an artificial neural network (ANN) to create a regression model for predicting continuous numerical values. The ANN learns from input-output data pairs, adjusting its weights and biases to approximate the relationship between the input variables and the target variable. This makes neural networks useful for predictive and forecasting applications.
Neural network regression is a supervised learning method that’s well-suited for problems where a traditional regression model can’t find a solution. It requires a tagged dataset with a label column that’s a numerical data type. The input features can be categorical or numeric, but the dependent variable must be numeric. If the output variable is categorical or binary, the ANN will act as a classifier.
Support Vector Regression (SVR)
Support Vector Regression (SVR) is a machine learning technique that uses Support Vector Machines (SVMs) to predict continuous numeric values. It’s an extension of SVM, which is mainly used for classification tasks. SVR is useful for regression tasks where linear regression may not be sufficient, such as when data has complex relationships or non-linear patterns.
SVR’s goal is to find a function that predicts a target variable while maximizing the margin between the predicted values and the actual data points. It does this by identifying a “margin” around the predicted regression line and fitting the line within that margin while minimizing prediction error. SVR uses an ε-insensitive loss function to penalize predictions that are farther from the desired output, and the width of the tube is determined by the value of ε. SVR also assigns zero prediction error to points that lie inside the ε-insensitive tube, and penalizes slack variables proportionally to their ξ. This feature helps SVR handle overfitting more effectively than other regression models.
SVR has several advantages, including: Robustness to outliers, Easy-to-update decision model, Excellent generalization capability, High prediction accuracy, and Easy implementation.
SVR’s ability to handle both linear and non-linear data makes it a versatile tool for a variety of real-world applications, such as financial forecasting, stock price prediction, economics, and engineering.
NN vs. Random Forest
When applied to somewhat limited data set availability, Random Forest machine learning techniques out-perform neural networks. Compared to a neural network, a random forest model generally offers advantages in terms of interpretability, ease of use, faster training time, and better performance with smaller datasets, making it a preferred choice when understanding feature contributions and working with limited data is crucial, while neural networks often excel in complex pattern recognition with large datasets where interpretability is less critical.
Key advantages of Random Forest over Neural Networks:
Interpretability:
Random forests are inherently more interpretable as you can easily examine the decision rules within each tree to understand which features are most important for predictions, while neural networks often function as “black boxes” with less clear feature relationships.
Data Requirements:
Random forests can perform well with smaller datasets, whereas neural networks typically require significantly more data to train effectively and avoid overfitting.
Training Speed:
Random forests generally train much faster than neural networks, especially on large datasets, due to their simpler structure and less complex computations.Random forests generally train much faster than neural networks, especially on large datasets, due to their simpler structure and less complex computations.
Less Preprocessing:
Random forests often require less data preprocessing compared to neural networks, which may need extensive feature engineering to optimize performance.
Robustness to Outliers:
Random forests are generally more robust to outliers in data compared to neural networks.

STEP 3 NCCN guidelines: Early detection evaluation. In this step there is full reliance upon PSA and/or DRE taken at recommended intervals based upon risk category and age. For those patients with average risk and PSA<1 ng/ml and normal DRE (if done), repeat PSA and/or DRE at 2-4 intervals. Logical; however, for patients of average or high risk but with PSA,= 3ng/mL and DRE normal (if done), then repeat same tests at 1-2 year intervals. For those less than 75 years of age, if PSA>3 ng/ml and/or a VERY suspicious DRE; OR those greater than 75 and PSA>=4 ng/ml OR VERY suspicious DRE, then further evaluation is indicated for biopsy.
So in the end of these processes, the added cost of genetic testing and/or office visits has placed the patient in average or high risk categories based largely upon age and history/gene mutations, and suggests either monitoring with PSA and/or DRE OR if warranted, Advance to STEP 4, Further Evaluation and Indications for Biopsy.
PAUSE: In this guideline, there remains complete reliance upon PSA tests and DREs for early detection evaluation despite the facts that neither, nor their combination has a sensitivity-specificity much greater than 50%.
What if the above screening tests don’t reveal a cancer? The NCCN is recommending waiting another 1-2 years. Imagine the number of cancers left growing in this time-frame, and imagine that there was a better screening method.
STEP 4 NCCN guidelines: After repeat PSAs, DREs, then consider mpMRI or biomarkers that “improve the specificity of screening” such as Select MDx, 4Kscore, ExoDx, etc. prostate tests.
PAUSE: Regarding these biomarkers – they are very expensive. Who’s paying and at what benefit? Let’s focus on the benefit. In general these tests reveal a statistical score based upon one’s having PCa or susceptibility to having PCa. Even if the score is suggestive of prostate cancer, the next step is to get an MRI “if available” and/or proceed with an image-guided biopsy. Here’s the fine print on page 9 of the guidelines. “It is not yet known how such tests could be applied in optimal combination with MRI.”
STEP 4 concludes with STEP 5, Management: After the MRI or other biomarker, the patient is now considered either high or low suspicion for clinically significant prostate cancer (CSPC). The low risk classification leads to periodic follow-up using PSA/DREs again. If high, image-guided biopsy or transperineal approach with MRI targeting or without MRI targeting. Another words, they place no standard on the biopsy technic despite the published rather poor results of non-targeted standard 12 and 20 core biopsies.
DISCUSSION:
The above illustrates a number of fallacies and significant waste of medical resources and time. It is now well established that PSA is useful only in adding to the confidence of diagnosing cancer with the PSA density having some positive correlation to PCa; however, one has to have an accurate measurement of the organ volume and that also presents challenges and huge variations in accuracy amongst physicians performing manual measurements via MRI. DRE is only useful when a significant lesion is located in the posterior aspect of the gland; hence, nearly all anterior lesions are missed. Yet, the guideline heavily relies upon these antiquated non-specific, non-sensitive screening tests to guide a patient through early detection and diagnosis.
The argument about a better biomarker has been resolved. MRI plus a proven Detection and Diagnostic AI software can not only provide sensitivity-specificity results in the mid-90th percentile (Standalone AUROC that created physician improvement noted in this reference) [2], but also establish location, size, and classification of the suspicious lesion(s), in addition to the accurate volume of the gland – this without additional data such as the serum PSA or the expensive genetic tests or biomarkers.
The desired results of Prostate Cancer diagnoses are to have more definitive/accurate and early detections and/or confidence that the patient is cancer free. Moving the needle towards attaining these goals is the role of Artificial Intelligence in MRI interpretations.

MRI, and particularly multi-parametric MRI (mpMRI) has been widely published in recent years as THE biomarker for PCa. From an overview of several years of recent European peer-reviewed literature published over one year ago, “Multi-parametric magnetic resonance imaging is an emerging imaging modality for diagnosis, staging, characterization, and treatment planning of prostate cancer….There is accumulating evidence suggesting a high accuracy of mpMRI in ruling out clinically significant disease. Although definition for clinically significant disease widely varies, the negative predictive value (NPV) is very high at up to 98%.” Translation: if MRI does not detect clinically significant cancer, then one is assured at 98% confidence that they don’t have significant cancer!
The European studies have been mirrored by many in the USA. This from a leading researcher, Dr. Dan Margolis, at UCLA: “MRI can identify most men who would not benefit from biopsy, and can identify the index lesion in most men who would.” Based upon an extensive literature review and presented in June 2015, this was the overview of the standard of care at the time.
P hysical exam (DRE) + serum analysis (PSA)
•If either are abnormal → systematic biopsies
* >1M American men annually have an elevated PSA but negative biopsies
* False negative rate up to 47% depending on series
•Also risk of “over diagnosis:” assuming low grade disease on biopsy belies hidden aggressive cancer


Measuring performance in prostate cancer detection and diagnosis
Measuring performance in prostate cancer detection and diagnosis
The literature is rife with different metrics for describing the performance of radiologists or AI algorithms in diagnosing prostate cancer, and it is important to understand how these are generated and what their limitations are. The most basic assessment as applied to the binary question of “is there cancer” defines “diagnosis”, which is at the case level. This can be assessed based on the confusion matrix (Fig. 1), a 2 × 2 table with the number of actual positive and actual negative cases on one axis, and the number of predicted positive and predicted negative cases on the other axis. As can be seen, the four boxes then contain the number of true positives (TP), true negatives (TN), false positives (FP) and false negatives (FN). From this, the standard statistical measures of sensitivity (or true positive rate), which is the TP divided by all positives = TP/(TP+ FN), and specificity (or true negative rate), which is the TN divided by all negatives = TN/(TN+FP), can be calculated. Many studies report sensitivity and specificity results for their readers or their AI algorithms, and in general a “good” reader or AI algorithm has a combination of high sensitivity and high specificity. Other metrics, such as positive and negative predictive value (PPV, NPV) are also often reported in studies, again derived from the confusion matrix, with PPV being TP divided by all those called positive = TP/(TP + FP) and NPV being TN divided by all those called negative = TN/(TN + FN).
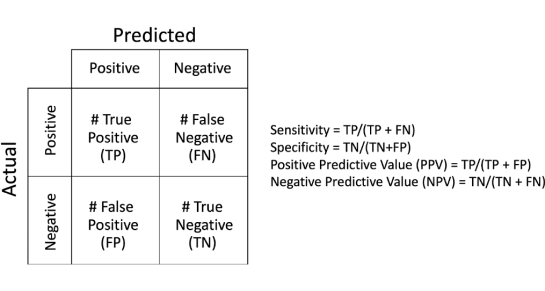
Fig. 1. Confusion Matrix and the definitions for sensitivity, specificity, positive and negative predictive value.
ROC analyses
Applying such metrics may seem straight-forward, however there are numerous nuances to consider. First, how do we make the binary decision “positive” or “negative”? In fact, PI-RADS does NOT make such a decision as it is basically a five-point scale describing the likelihood of the patient having csPCa. Assume for a moment we call only PIRADS 5 lesions “positive”. Provided we have ground truth (e.g. biopsy, explant pathology), we can then calculate sensitivity and specificity. Alternatively, we could choose to call PIRADS ≥ 4 lesions positive, yielding a different sensitivity and specificity, and so on for PIRADS ≥ 3 lesions and
≥ 2 lesions. By doing this, we arrive at four different sensitivities and specificities corresponding to the different PIRADS thresholds. These values can be plotted on a Receiver Operating Characteristic curve (ROC), with the x axis (1 – Specificity) and the y axis Sensitivity, as shown for hypothetical data in Fig. 2. Note that by calling all PIRADS ≥ 2 positive our sensitivity is very high, but at the price of low specificity. Conversely by only calling PIRADS 5 lesions positive, our specificity is high, but our sensitivity suffers. The diagonal line is known as the line of “no discrimination”, i.e. purely random; points to the left of this line are better than random, and points to the right worse than random, with top left (0,1) being perfect. With AI, there may be a more continuous vari- able characterizing the probability of prostate cancer, for example a continuous probability ranging from 0 to 1. Under these circumstances, many more points can be generated to fill-in the ROC curve such that it is smoother and can help to choose the optimum threshold given the desired outcome, or compare between different readers/techniques. A useful and often used numerical measurement of performance well suited to comparison is the “area under the (ROC) curve”, or AUC, illustrated as the shaded area in Fig. 2, which ranges from 0≥ 2 lesions. By doing this, we arrive at four different sensitivities and specificities corresponding to the different PIRADS thresholds. These values can be plotted on a Receiver Operating Characteristic curve (ROC), with the x axis (1 – Specificity) and the y axis Sensitivity, as shown for hypothetical data in Fig. 2. Note that by calling all PIRADS ≥ 2 positive our sensitivity is very high, but at the price of low specificity. Conversely by only calling PIRADS 5 lesions positive, our specificity is high, but our sensitivity suffers. The diagonal line is known as the line of “no discrimination”, i.e. purely random; points to the left of this line are better than random, and points to the right worse than random, with top left (0,1) being perfect. With AI, there may be a more continuous vari- able characterizing the probability of prostate cancer, for example a continuous probability ranging from 0 to 1. Under these circumstances, many more points can be generated to fill-in the ROC curve such that it is smoother and can help to choose the optimum threshold given the desired outcome, or compare between different readers/techniques. A useful and often used numerical measurement of performance well suited to comparison is the “area under the (ROC) curve”, or AUC, illustrated as the shaded area in Fig. 2, which ranges from 0
ROC Curve
1 –Specificity (False Positive Rate)
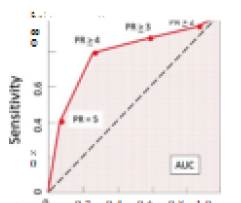
Fig. 2. Hypothetical example of Receiver Operating Charateristic (ROC) curve. Area under the curve (AUC) represented by red shading.
to 1. AUC provides a more global picture of performance across differing thresh- olds. A perfect score would be 1.0, and the literature often describes prostate AI achieving AUC > 0.9; however, we will further discuss how these values are significantly influenced by the exact mechanism by which the ROC/AUCs were measured; meaning that the AUC values reported cannot be directly compared unless the exact methods are also shared and identical.
PCA case level vs. lesion level diagnosis
Another important consideration when examining how radiologists or algorithms perform has to do with how we define what constitutes a “correct” diagnosis? Considering only a single diagnosis for the case (case level diagnosis), calling a malignant lesion somewhere in the prostate is considered “correct” even if the identified lesion is a false positive and the true malignant lesion is totally missed. On the other hand, we could score each identified lesion individually and use this to determine our performance (lesion level diagnosis). How we chose to do our evaluation has the potential to become even more problematic with AI, which may perform the analysis on a pixel-by-pixel level. Should we somehow try to do the analysis of truth pixel-by-pixel (and is that even possible given what we have for truth?). Do we consider only the highest probability pixel in a “suspicious” region? Or a cluster of higher prob- abilities of a certain size? These are all different approaches that will lead to different results.
Establishing ground truth and scoring system
All of this introductory information has been provided as back- ground for how to evaluate and analyze a comparative study of radiol- ogists performing PIRADS reads with and without the help of a prostate CADe/CADx system. Given all of the variables discussed, it is clear that one must establish a solid clinical study so as to minimize measurement errors and follow a common standard. We believe the radiology com- munity thus far lacks such guidance that standardizes the methodologies for:
- Measuring a non-continuous diagnostic system such as PI-RADS
- Generating ROC curves with fixed numbers of evaluation points (pixels, 3D grids, PI-RADS sub-regions, etc.)
- Determining how to evaluate reader and software detection of le- sions and defining what is truly a “hit” versus “miss” of a lesion based upon the granularity of division of the prostate, or “how you slice it”
- How best to ethically establish and accurately place three- dimensional pathology ground truth points or volumes within the three-dimensional MRI data set
- And perhaps most challenging of all, how to establish whether non- suspicious (unsampled) tissues and patient cases are truly negative for cancer
- Although the FDA provides guidance documents on Clinical Performance Assessment of CAD radiologic software, as well as guidance on establishing clinicals studies for Computer-assisted Detection Devices Applied to Radiology Images, the detailed methods outlined above are left to the submitting medical device companies. It is therefore highly unlikely that any two radiological CAD devices or peer-reviewed papers discussing the performance of a device can be directly compared because of the significantly different outcomes resulting from the non-standardization of the above methods and procedures.
Variations in AI systems based upon Installation
Electronic data connection between the MRI system and the AI software is obviously necessary in order to feed the software with MRI studies and obtain the resulting outputs. These connections can come via three different methods:
- direct secure VPN tunnel of PACS or MRI System to the AI provider’s PACS;
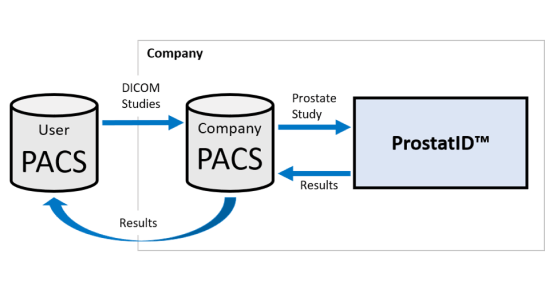
- connection from the user’s PACS or MRI System to a third-party AI Platform typically installed behind the hospital of MRI facility’s firewall;
- connection from the PACS or MRI System to a separate stand-alone computer system containing the provider’s AI.
Components of working AI systems (how they work)
This paper has described the various detection models, also referred to as “inference models”; however, many other steps must be taken to ensure safety, security and efficacy of the software, not to mention, consistent operation.
As an example, the ProstatID® (Bot Image, Inc., Omaha, NE) software algorithm consists of six functional steps as indicated in the Architecture Design Chart (Figure below), and summarized below.
- Automatic Detection of Prostate Input Images.
- Image quality testing for Complete Study of 3 series, three complete series of equivalent total slice volume, minimum resolution.
- Prostate segmentation, feature calculation and cancer classification
- CAD Report Generation.
- Return DICOM outputs to Users
- Delete Study

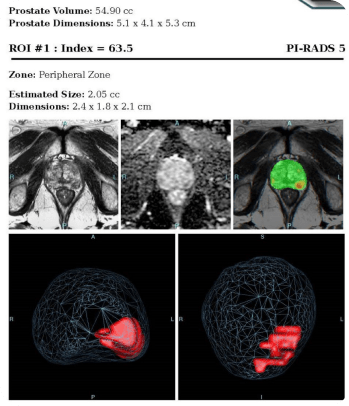
CAD Report Generation of Algorithm Output
After creation of the color overlay in Function 3, the algorithm proceeds to generate the report (Figure below) consisting of the colorized probability map, correlated to classification of cancerous tissue, overlaid on a copy of the T2-wieghted image set, and a 3D rendition of each suspect lesion with probability greater than 62%.


Performance Comparisons of Boosted Parallel Random Forest, NN, Standard Random Forest and others in PCa detection – ISMRM
A test comparing the performance of trained models of prostate cancer detection models using different types of machine learning was conducted and reported in an academic paper presented at the International Society of Magnetic Resonance in Medicine, Annual meeting 7-12 May 2022, London, UK.
Comparison of machine learning methods for detection of prostate cancer using bpMRI radiomics features Ethan J Ulrich1, Jasser Dhaouadi1, Robben Schat2, Benjamin Spilseth2, and Randall Jones1; 1Bot Image, Omaha, NE, United States, 2Radiology, University of Minnesota, Minneapolis, MN, United States
The following are excerpts from the paper above which can be viewed within the ISMRM Book of Abstracts.
Synopsis
Multiple prostate cancer detection AI models—including random forest, neural network, XGBoost, and a novel boosted parallel random forest (bpRF)—are trained and tested using radiomics features from 958 bi-parametric MRI (bpMRI) studies from 5 different MRI platforms. After data preprocessing—consisting of prostate segmentation, registration, and intensity normalization—radiomic features are extracted from the images at the pixel level. The AI models are evaluated using 5-fold cross-validation for their ability to detect and classify cancerous prostate lesions. The free-response ROC (FROC) analysis demonstrates the superior performance of the bpRF model at detecting prostate cancer and reducing false positives.
Results
The bpRF model, which extracts intensity and texture features for detecting prostate cancer based upon Lay’s model from the NIH, outperforms other machine learning methods (random forest, UCLA’s neural network, and XGboost – a gradient boosting machine) as demonstrated by an improved FROC performance indicating fewer false positives and false negatives. Additionally, the algorithm has demonstrated the potential of more accurately depicting the actual size and outline of the cancerous lesions.
The performance metric for FROC is the weighted alternative FROC (wAFROC) figure of merit and is analogous to the ROC AUC. The bpRF model (from ProstatID of Bot Image, Inc., Omaha, NE) had significantly higher performance when compared to NN (p=0.007), RF (p=0.003), and XG (p=0.002) after adjusting for multiple comparisons.

Detections are evaluated at each biopsy location and local maxima within the predicted probability map. False positives are defined as detections at biopsy sites with combined Gleason score < 7 or a local maximum that is more than 6 mm from a known lesion. Curves and the performance metric (θ) are the average of the cross-validation folds. NN = neural net, XG = XGBoost, RF = random forest, bpRF = boosted parallel random forest.
Discussion
While all models demonstrated similar performance when evaluating at the lesion-level (ROC analysis), bpRF outperforms other models on FROC analysis. This indicates that the bpRF model produced fewer false positive detections at equal sensitivity.
These systems utilize the lesion identification assistance of AI powered MRI to provide targeting for needle and treatment probe placement while combining or fusing the MRI images to real-time US images and viewing the needle/probe placement on a computer screen to ensure placement within the MRI targets.
- What guidance, if any, was used to target the biopsies?
- How did the interventionalist know that he/she hit the target?
- How were the biopsies taken and how large of samples?
- How accurate was the method used?
- How experienced was the pathologist in interpreting cellular mounts?
The literature has demonstrated the effectiveness of AI used in interpreting and classifying cellular slide pathology; hence, further improving the standard of care in prostate cancer detection and classification.
